Deep Reinforcement Learning in Imperfect Information Games: Texas Hold’em Poker
Many real-world applications can be described as large-scale games of imperfect information. This particular set of problems is challenging due to the random factor that makes even adaptive methods fail to correctly model the problem and find the best solution. In this paper, we are going to take a look at one of the most popular game of such type, no limit Texas Hold’em Poker, yet unsolved, developing multiple agents with different learning paradigms and techniques and then comparing their respective performances.
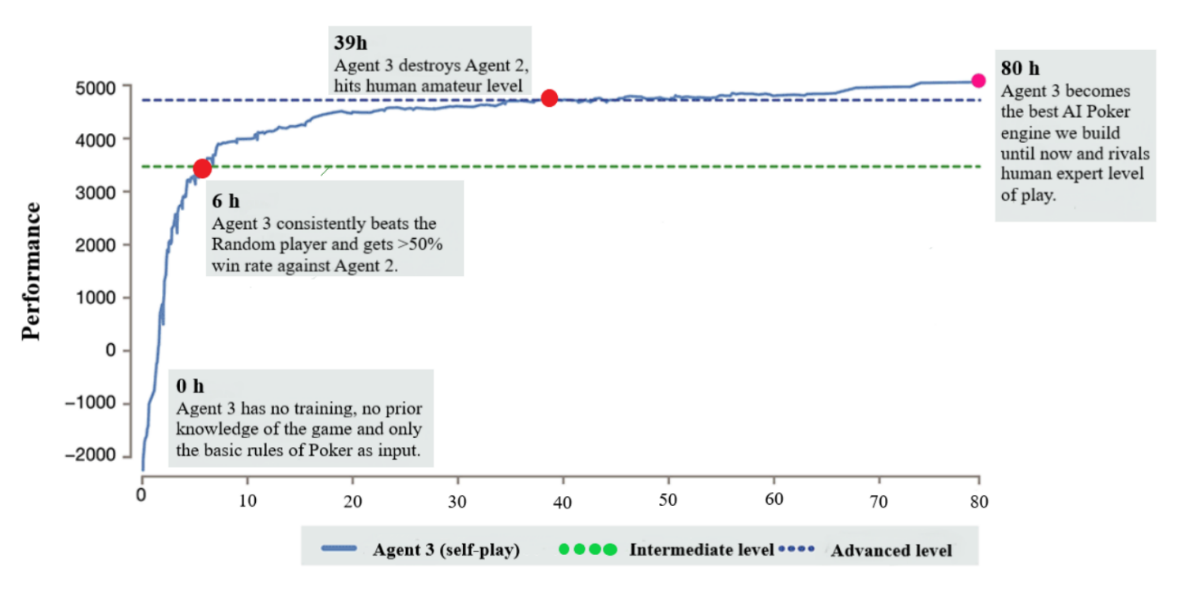
Moreover, we are introducing a new approach to learning approximate Nash equilibria with very limited prior domain knowledge, in an attempt to solve the heads-up variant. Our method combines continuous-time dynamic fictious self-play with gradient play and reinforcement learning through deep neural networks. When applied to no-limit hold’em Poker, deep reinforcement learning agents clearly outperform agents with a more traditional approach. In turn, the ones trained through self-play drastically outperformed the ones that used fictitious play with a normal-form single-step approach to the game. Finally, our best self-play-based agent learnt a strategy that rivals expert human level.
#Presentation of the project

Note that for these experiments, we used a NVIDIA Tesla T4 Workstation with 32GB of RAM and a NVIDIA GTX 1050ti with 16GB of RAM, but the resulting artificial players can be run on a less impressive machine even without a GPU, with 8GB of RAM.
Although the results looked pretty successful, it is very hard to correctly assess the level of play of our best agents. Until we test them against a professional player or top computer programs like Hyperbolean, we can’t know for sure that they are indeed at top human level. Furthermore, due to time and hardware constrains, we couldn’t experiment on more iterations, we can maybe descend even more closer to a Nash equilibrium in optimal conditions. Improvements can also be made regarding the format of the game. All the agents were trained in heads-up, no-limit, 100-100 starting stack with 5 small blind formats, but for more general play, it is recommended to consider the small blind as percentage of the starting stack.
Games today form a multi-billion-dollar industry, and Reinforcement Learning can be a very effective tool for pro-profit organizations in developing agents that test the internal balance of each product. The most popular games go through constant updates, companies always introduce new features, introduce new characters, maybe with different abilities, therefore there is always a risk to break the game, from a balance point of view. Thus, the testing phase can be fully automated by intelligent agents interacting with the new environment, which is the next patch game, to make sure that the design decisions of the new components do not make the game unplayable.
You can play against Rosita here (currently disabled) !

Tidor Pricope
This first started as a decent thesis subject, but the more I looked into it, the more I fell in love with the subject and developed some original stuff !
Tidor Pricope
Hope you like this guys !
Reply